RepoDex
命名:RepositoryIndex——仓库索引聚合。
为什么要开发此项目
在日常开发中,开发者在 GitHub 上建立了大量的仓库,其中有各种代码文件、文档资料、资源文件等。GitHub 本身缺少跨仓库、跨分支的全局文件搜索能力,这给开发者带来了诸多不便。
此外,对于中文用户,这些文件中不乏中文文件名的内容,GitHub 也不支持拼音模糊搜索,进一步限制了用户的检索效率。
为此,我开发了本项目,基于 GitHub Actions、Cloudflare Workers 和传统前端技术(当前,后期有向框架迁移的准备),实现了一套跨仓库、跨分支的多维度模糊搜索系统,以提升用户在 GitHub 上的文件检索效率。
本项目以易配置、零成本的思想开发,在正常使用情况下,远不可能达到 GitHub Actions 和 Cloudflare 的免费额度。您可以放心地按照本文流程部署项目,无须担心产生任何成本。
项目效果速览
移动端的优良适配
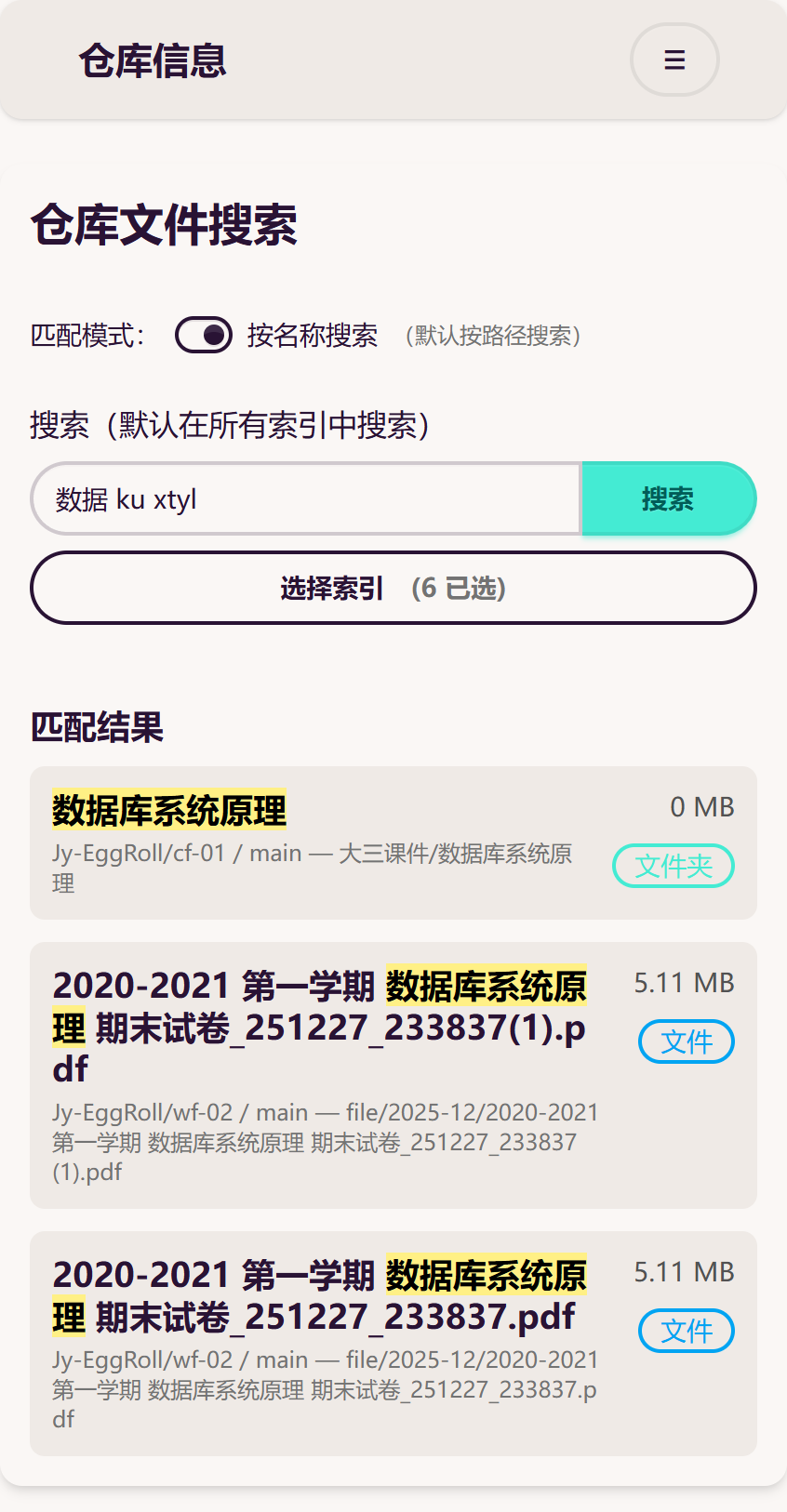
上图采用“按名称搜索”,您可以从中看出中英文、全拼、简拼的匹配效果。
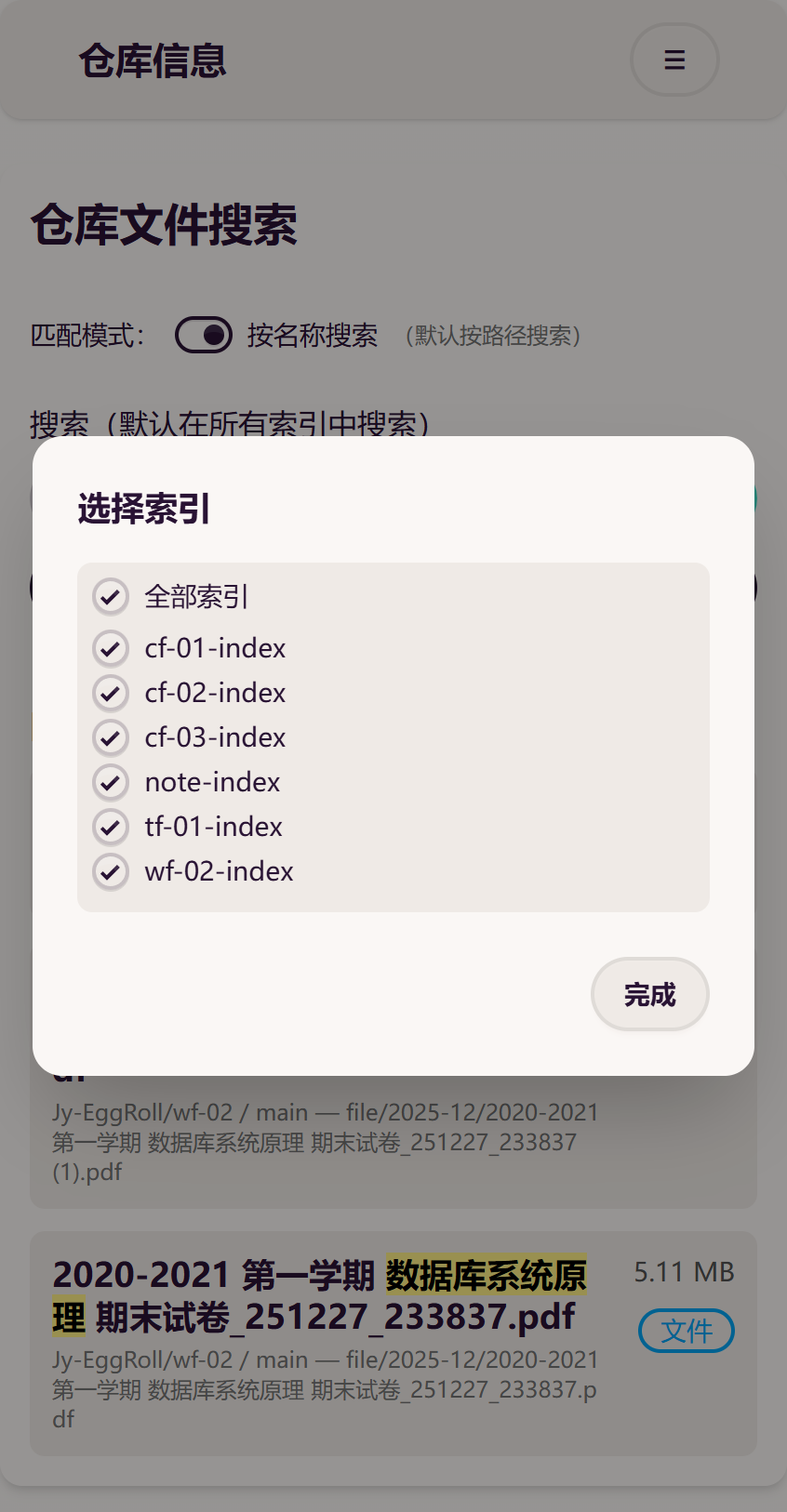
本项目支持选择索引,默认全选。选中或取消选中后会在短暂的防抖延时后自动刷新结果列表。
美观的宽屏布局
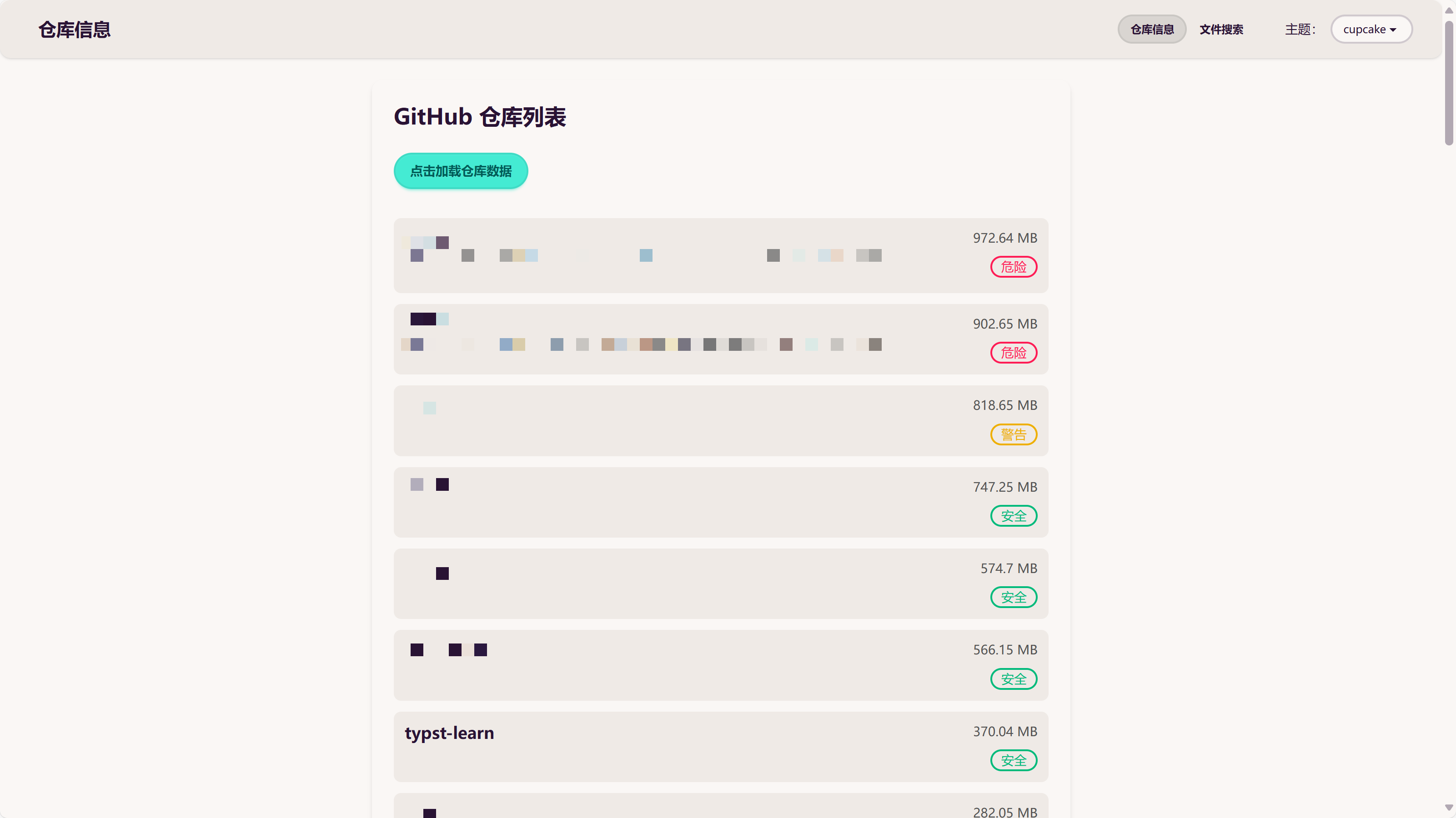
对于仓库显示的标签,>900MB 是危险,800~900MB 是警告,<800MB 是安全。用户不应该存储大于 1GB 的仓库,这其中有很多原因,此处不再赘述。
其他特点
- 不论是仓库还是文件,都支持点击直达 GitHub。
- 文件默认检测所有分支(事实上,这是由索引决定的)
- 主题切换(当前仅支持手动,后续维护)
项目优点速览
- 拼音搜索与模糊搜索:用户只需要记得文件名中的一些关键词,就可以模糊查找到任何文件。默认启用“以路径搜索”,即使用户的关键词没有体现在文件名本身中,只要用户的分类是合理的,即关键词体现在路径中,也可以搜索到文件。
- 高性能:Cloudflare Workers 配合 Cloudflare KV,搜索速度很快。此外,受益于 Cloudflare 自身在全球的强大 CDN,网页本身的访问速度也并不慢。从 Cloudflare 向 GitHub 发起请求的速度也比较理想。
- 私密性极强:本项目可接入任意私有仓库,搜索前端页面采用 HTTPS 加密鉴权(Hono 框架),只有同时获得 Cloudflare 机密中用户名与密码的用户,才可以访问(通常也就是用户自己)。若用户担心用户名与密码同时泄露,可以随意在 Cloudflare 后台更改。本项目直接保护网站的根路径,在未授权情况下无法访问任何 api 与页面资源,这甚至杜绝了被攻击的风险。
先决条件
用户只需要一个 Cloudflare 账号,不需要绑定银行卡等复杂操作。
如何使用该项目
请自行先注册一个 Cloudflare 账号。地址:https://dash.cloudflare.com/login。
Fork 本项目

如果您愿意为本项目点一个 star,我将非常感激。
创建 Workers 并绑定到 GitHub
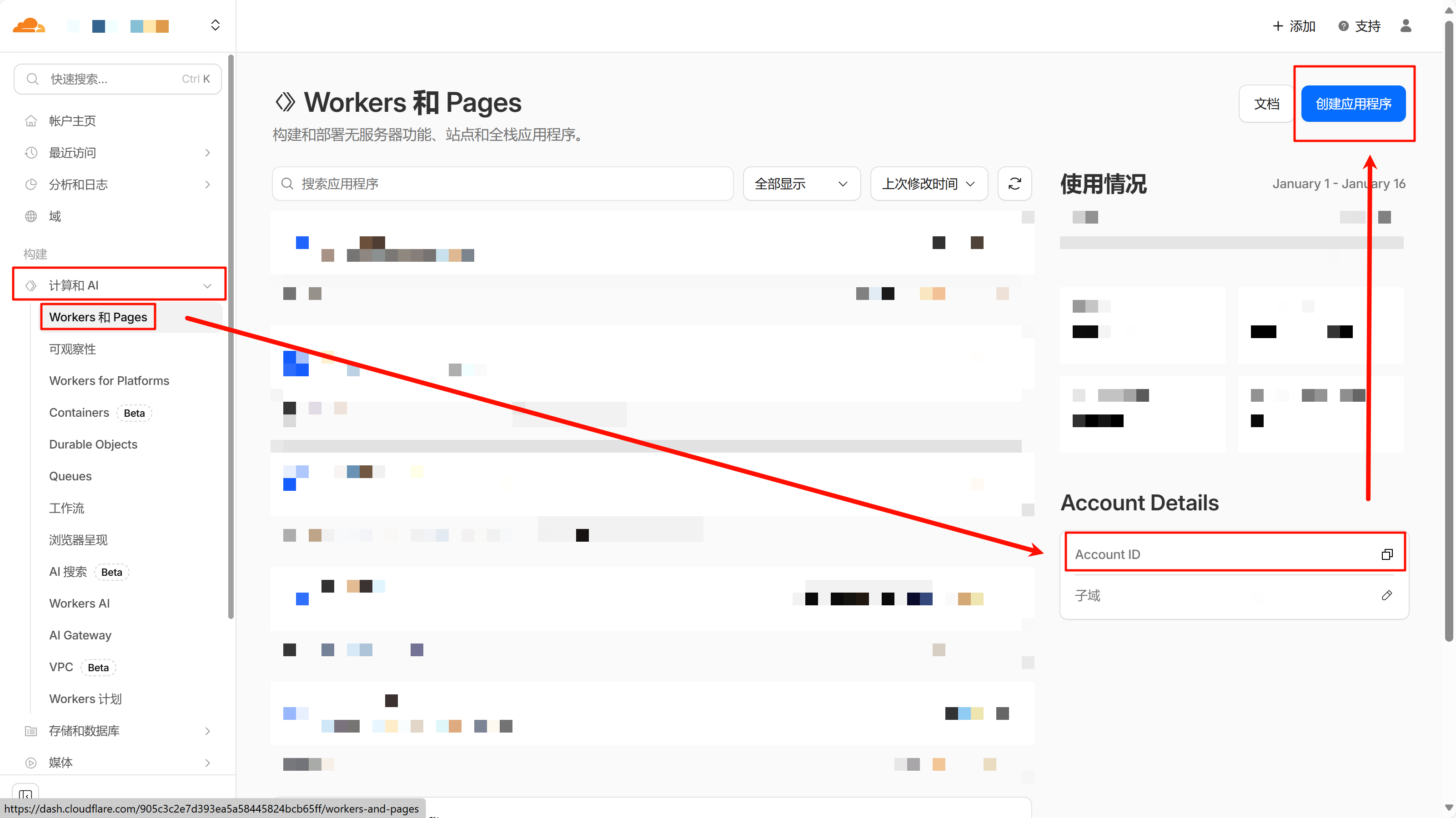
请复制 Account ID 【信息 1】并记录到安全的地方,后续将使用该信息。
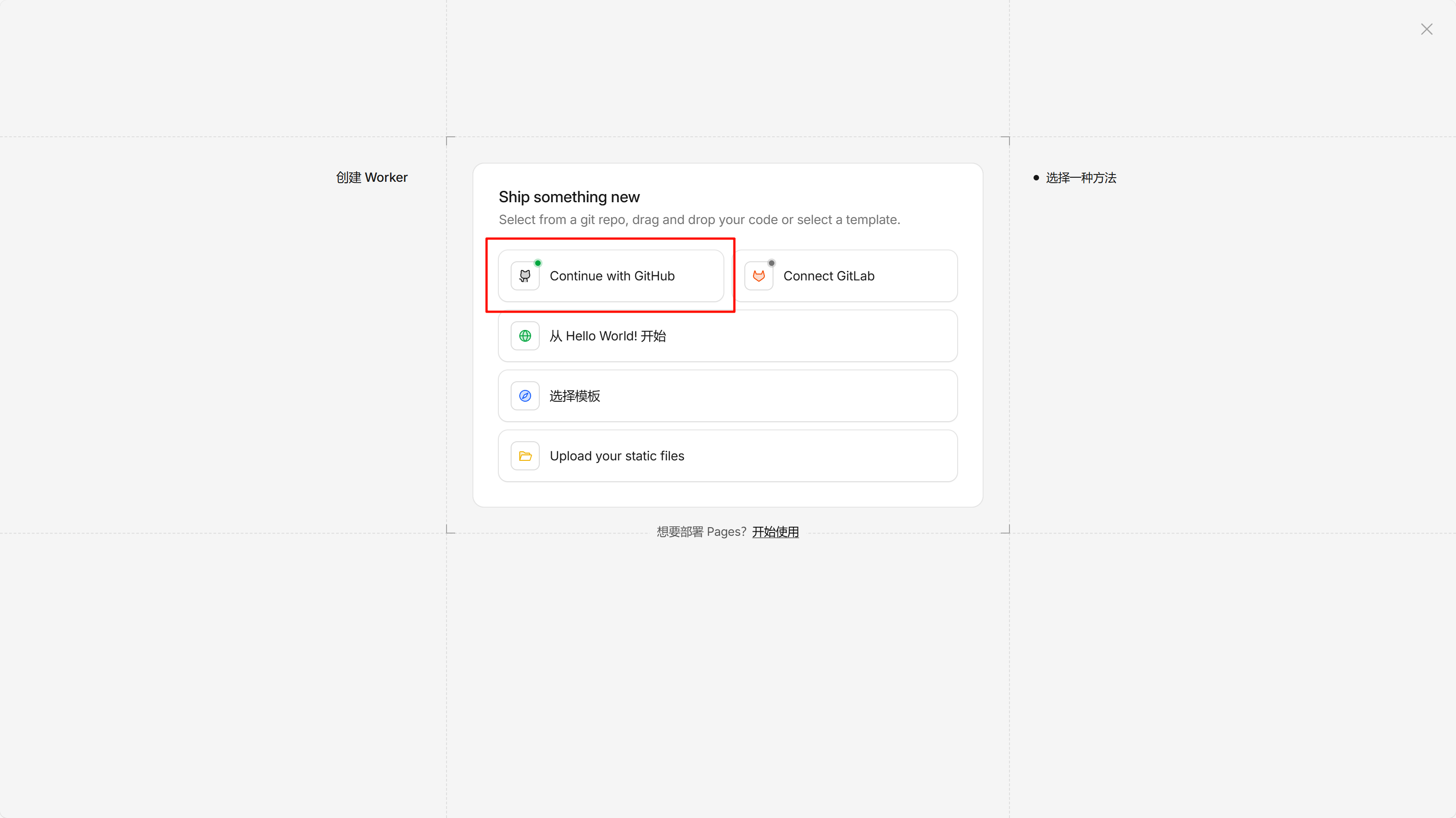
请连接到 GitHub,如需授权,请放心授权。连接后选择自己 Fork 的项目即可。
选择后直接部署即可,不需要改动任何默认值。
创建 Workers KV
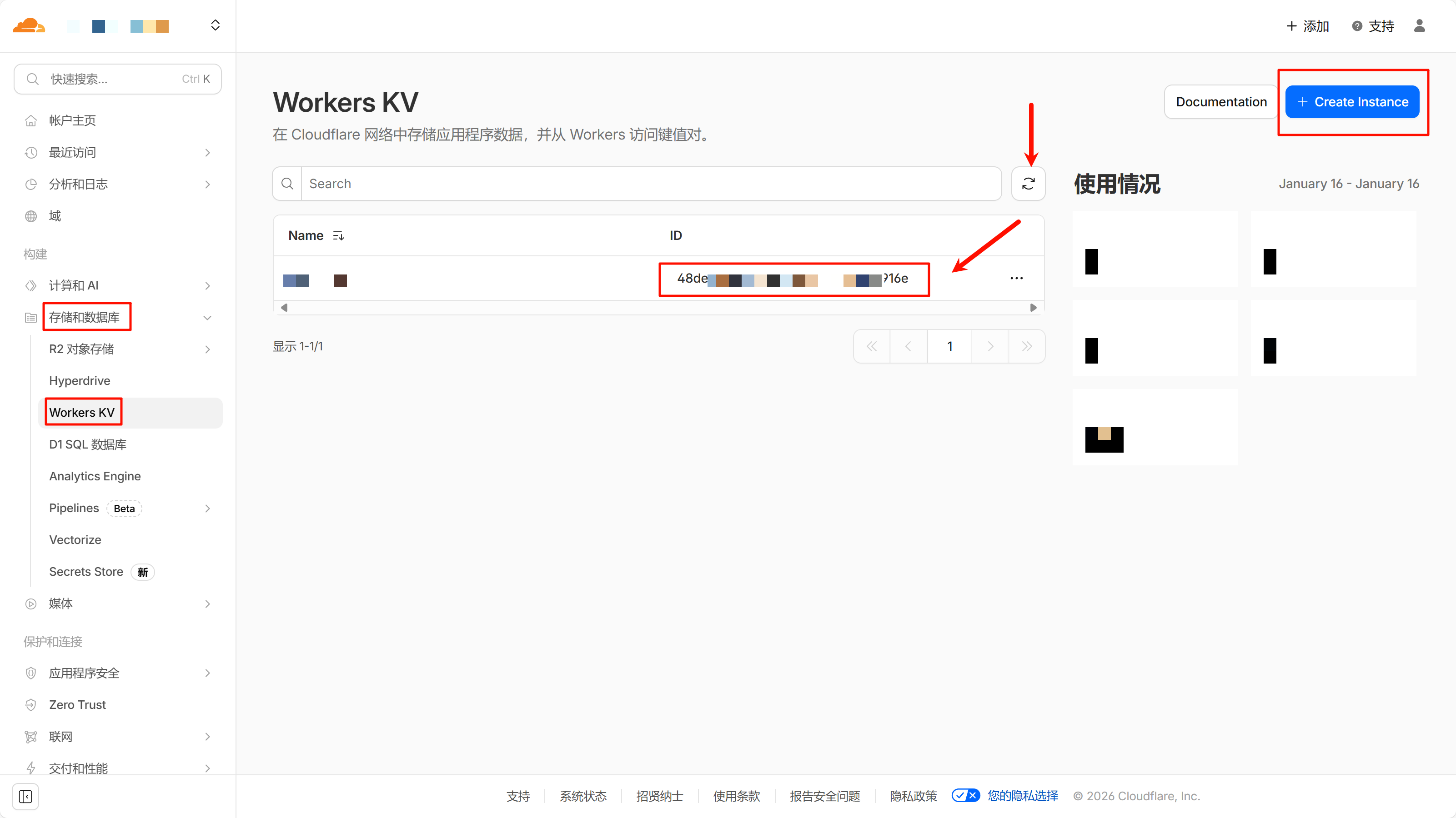
请按照图中指示创建 KV,名称随意,刷新后点击 ID 即可复制 ID【信息 2】,请记录到安全的地方。
创建 Cloudflare Token
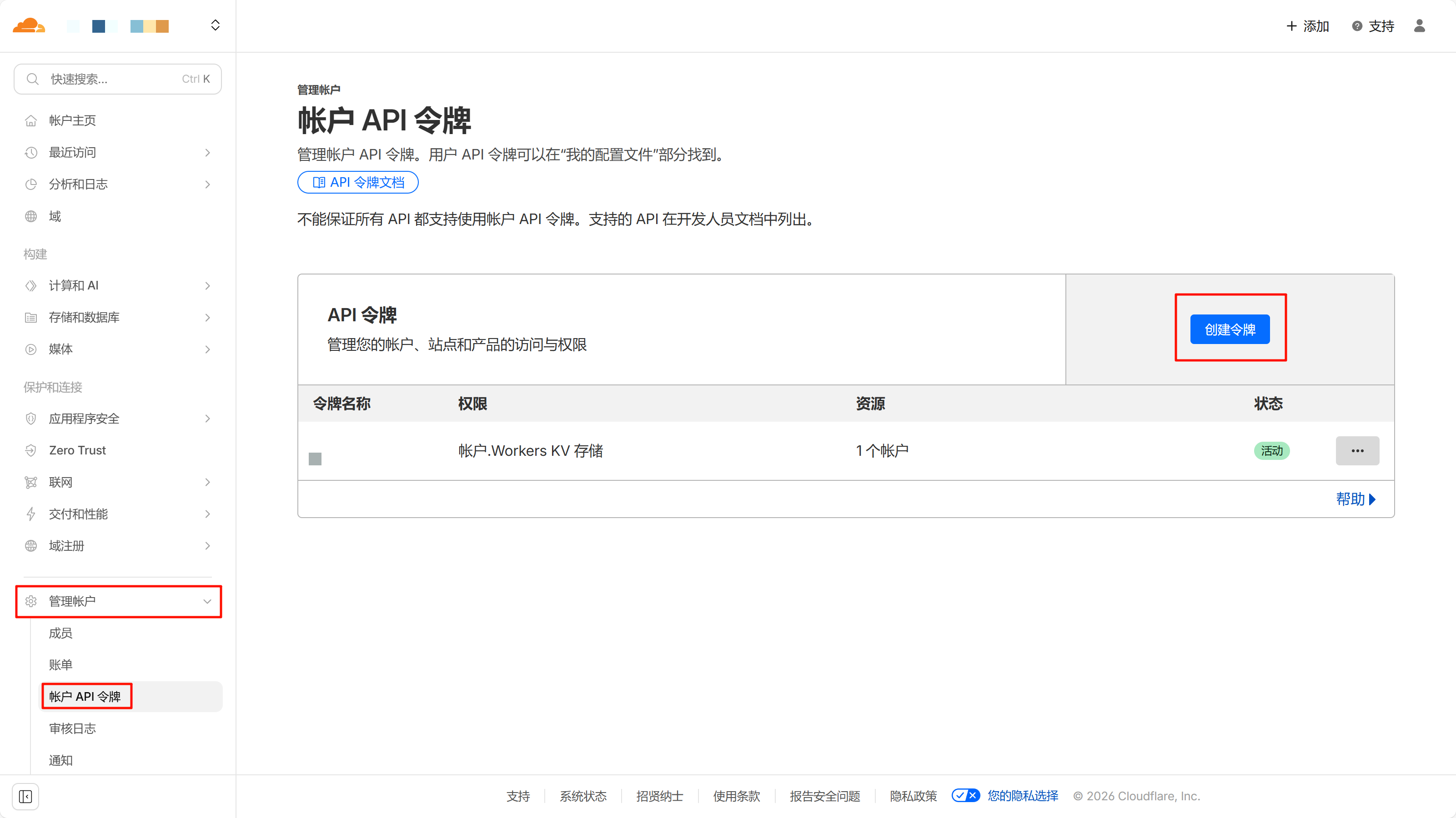
请按照图示创建拥有 Workers KV 存储权限的令牌。
令牌创建成功后只会展示一次,默认创建无限期令牌,请复制到安全的地方【信息 3】。
[!CAUTION]
请注意:令牌泄露后风险极大,请务必妥善保护!
创建 GitHub Token
请注意,本步骤在 GitHub 上进行。
地址为 https://github.com/settings/tokens。
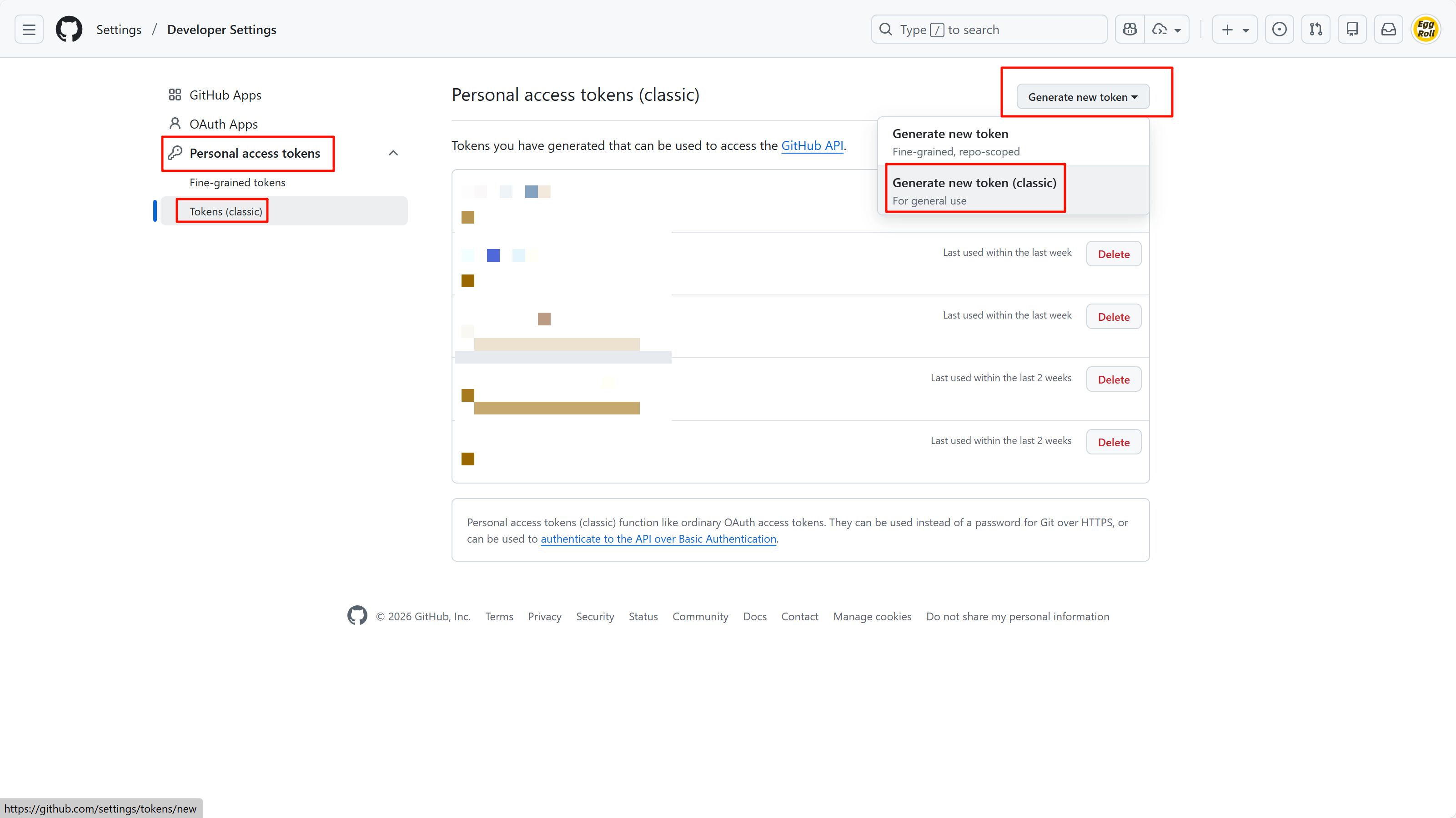
请按图中指引,创建拥有完整 repo 权限的 token,可以选择永不过期,但是务必妥善保存。创建后请复制【信息 4】。
[!CAUTION]
请注意:令牌泄露后风险极大,请务必妥善保护!
在需要接入搜索的仓库配置的内容
Secrets(机密)
创建机密的位置:
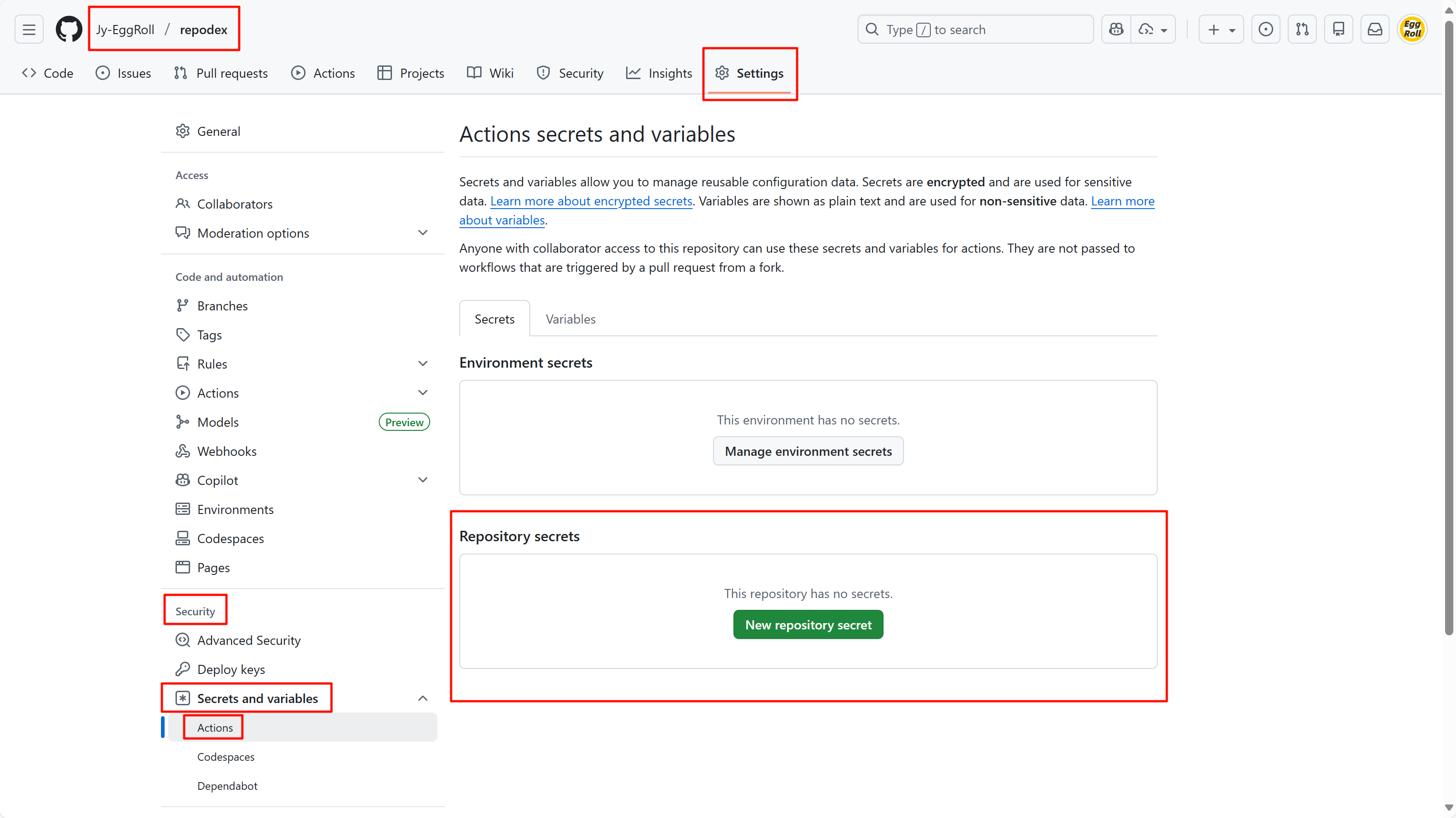
请注意,本处 repodex 仓库仅作为演示,需要配置机密的仓库是要接入索引的仓库,您想要在哪个仓库中搜索文件,就在哪个仓库中配置三个机密。
CF_ACCOUNT_ID:用于拼接推送时的链接,即上方【信息 1】。CF_NAMESPACE_ID:用于拼接推送时的链接,即上方【信息 2】CF_API_TOKEN:用于授权向 Cloudflare KV 推送数据,即上方【信息 3】
读者可能不解,为什么要配置三个机密,是否太过麻烦?答案是否定的,安全大于一切。诚然,可以把三个字符串写入一个变量,调用过程中拆分即可,但是用户如果修改了工作流而不自知,可能会意外泄露这些重要变量,而机密在工作流中始终显示为 ***。
文件
同样是在要接入索引的仓库配置,简单配置如下:
.github/workflows/generate-index-and-push.yml:自动化工作流配置文件,依赖上一步配置的机密。
请复制该完整路径,粘贴到:
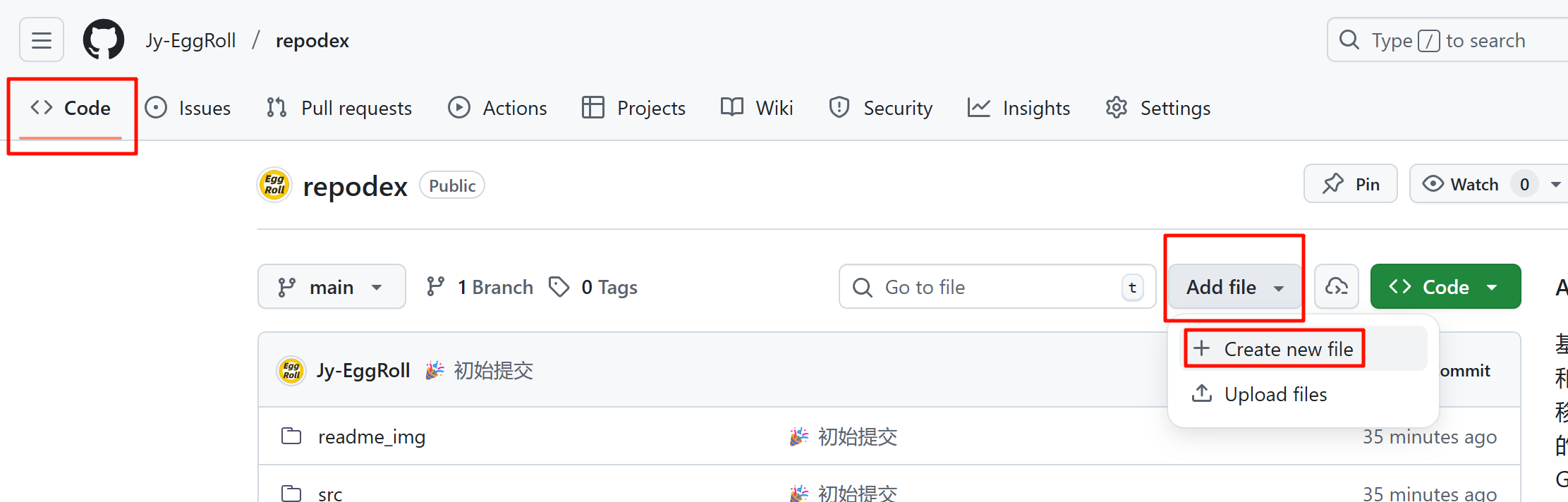
提交后,工作流将自动开始执行。
工作流内容如下,您可以一并复制。若您需要本地 yml 文件,请下载仓库 workflows 下的 generate-index-and-push.yml。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
|
name: Generate Repository File Index JSON and Push to KV
on:
push: # 任何推送操作都会触发,请注意不要在本工作流中执行向本仓库的推送操作,这可能造成工作流的循环触发
workflow_dispatch: # 允许手动触发工作流
jobs:
generate-and-push:
name: Generate Index and Push
runs-on: ubuntu-latest
steps:
- name: Check required secrets # 在用户未配置必要 Secrets 时提前失败,避免浪费资源
shell: bash
env:
CF_API_TOKEN: ${{ secrets.CF_API_TOKEN }}
CF_ACCOUNT_ID: ${{ secrets.CF_ACCOUNT_ID }}
CF_NAMESPACE_ID: ${{ secrets.CF_NAMESPACE_ID }}
run: |
missing=0
for name in CF_API_TOKEN CF_ACCOUNT_ID CF_NAMESPACE_ID; do
if [ -z "${!name}" ]; then
echo "Missing secret: $name" >&2
missing=1
fi
done
if [ "$missing" -eq 1 ]; then
echo "Required secrets are missing. Aborting workflow." >&2
exit 1
fi
- name: Checkout Source Code
uses: actions/checkout@v4
with:
path: source-repo
fetch-depth: 0
- name: Setup Python
uses: actions/setup-python@v5
with:
python-version: '3.x'
- name: Generate JSON Index
id: generate_step
shell: python
working-directory: source-repo
run: |
import json
import subprocess
import os
import sys
# 设置 core.quotepath 为 false,强制 Git 输出原始的中文字符,而不是八进制转义序列,这可以保证索引中的中文文件名字全是正确的
subprocess.run(["git", "config", "--global", "core.quotepath", "false"])
def run_command(command):
try:
output = subprocess.check_output(command, shell=True, stderr=subprocess.PIPE)
return output.decode('utf-8').strip()
except subprocess.CalledProcessError as e:
print(f"Error executing: {command}", file=sys.stderr)
return ""
# 1. 获取仓库名并规范化文件名
repo_full_name = os.environ.get('GITHUB_REPOSITORY', 'unknown/repo')
repo_short_name = repo_full_name.split('/')[-1]
# 构造目标文件名:"仓库名-index.json"
json_filename = f"{repo_short_name}-index.json"
print(f"Target JSON Filename: {json_filename}")
# 2. 获取分支列表
raw_branches = run_command("git branch -r").split('\n')
target_branches = []
for b in raw_branches:
b = b.strip()
if not b or '->' in b: continue
# 提取纯净分支名
target_branches.append(b.replace('origin/', ''))
# 3. 遍历分支收集数据
branches_data_list = []
for branch_name in target_branches:
branch_data = {
"branch_name": branch_name,
"files": [],
"directories": []
}
# 获取文件(带大小)
files_cmd = f"git ls-tree -r -l --full-tree origin/{branch_name}"
files_output = run_command(files_cmd)
if files_output:
for line in files_output.split('\n'):
# 分割模式、类型、Hash、大小、路径
# 使用 maxsplit=4 防止文件名中的空格被错误分割
parts = line.split(maxsplit=4)
if len(parts) < 5: continue
if parts[1] != 'blob': continue # 只保留文件
size_str = parts[3].strip()
try:
size = int(size_str) if size_str.isdigit() else 0
except ValueError:
size = 0
original_path = parts[4]
branch_data["files"].append({
"name": os.path.basename(original_path),
"path": f"./{original_path}",
"size": size
})
# 获取文件夹
dirs_cmd = f"git ls-tree -r -d --full-tree origin/{branch_name}"
dirs_output = run_command(dirs_cmd)
if dirs_output:
for line in dirs_output.split('\n'):
parts = line.split(maxsplit=3)
if len(parts) < 4: continue
original_path = parts[3]
branch_data["directories"].append({
"name": os.path.basename(original_path),
"path": f"./{original_path}"
})
branches_data_list.append(branch_data)
# 4. 构建最终数据
final_json = {
"repository": repo_full_name,
"repository_short_name": repo_short_name,
"branches": branches_data_list
}
# 5. 为了方便后续步骤使用,将文件保存到上一级目录(runner workspace root)
# 这样即使我们在 source-repo 目录下,文件也能在 checkout 目标仓库时被轻松找到
output_path = os.path.abspath(f"../{json_filename}")
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(final_json, f, ensure_ascii=False, indent=4)
print(f"JSON generated: {output_path}")
# 6. 将文件名导出到 GitHub Actions 环境变量,供后续步骤使用
# 使用 GITHUB_ENV 文件写入环境变量
with open(os.environ['GITHUB_ENV'], 'a', encoding='utf-8') as env_file:
env_file.write(f"INDEX_FILENAME={json_filename}\n")
env_file.write(f"INDEX_FILE_PATH={output_path}\n")
- name: Upload index to Cloudflare KV
env:
CF_API_TOKEN: ${{ secrets.CF_API_TOKEN }}
CF_ACCOUNT_ID: ${{ secrets.CF_ACCOUNT_ID }}
CF_NAMESPACE_ID: ${{ secrets.CF_NAMESPACE_ID }}
INDEX_FILE_PATH: ${{ env.INDEX_FILE_PATH }}
INDEX_FILENAME: ${{ env.INDEX_FILENAME }}
run: |
echo "Upload ${INDEX_FILE_PATH} to Cloudflare KV namespace ${CF_NAMESPACE_ID}"
KEY="${INDEX_FILENAME%.*}"
resp=$(curl -sS -X PUT "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/storage/kv/namespaces/${CF_NAMESPACE_ID}/values/${KEY}" -H "Authorization: Bearer ${CF_API_TOKEN}" -H "Content-Type: application/json; charset=utf-8" --data-binary @"${INDEX_FILE_PATH}")
echo "$resp" | grep -q '"success":false' && { echo "Cloudflare API returned false" >&2; echo "$resp" >&2; exit 1; }
echo "Uploaded ${KEY}"
|
在 Cloudflare Workers 上需要配置的内容
本部分请注意,回到了 Cloudflare Workers 平台。
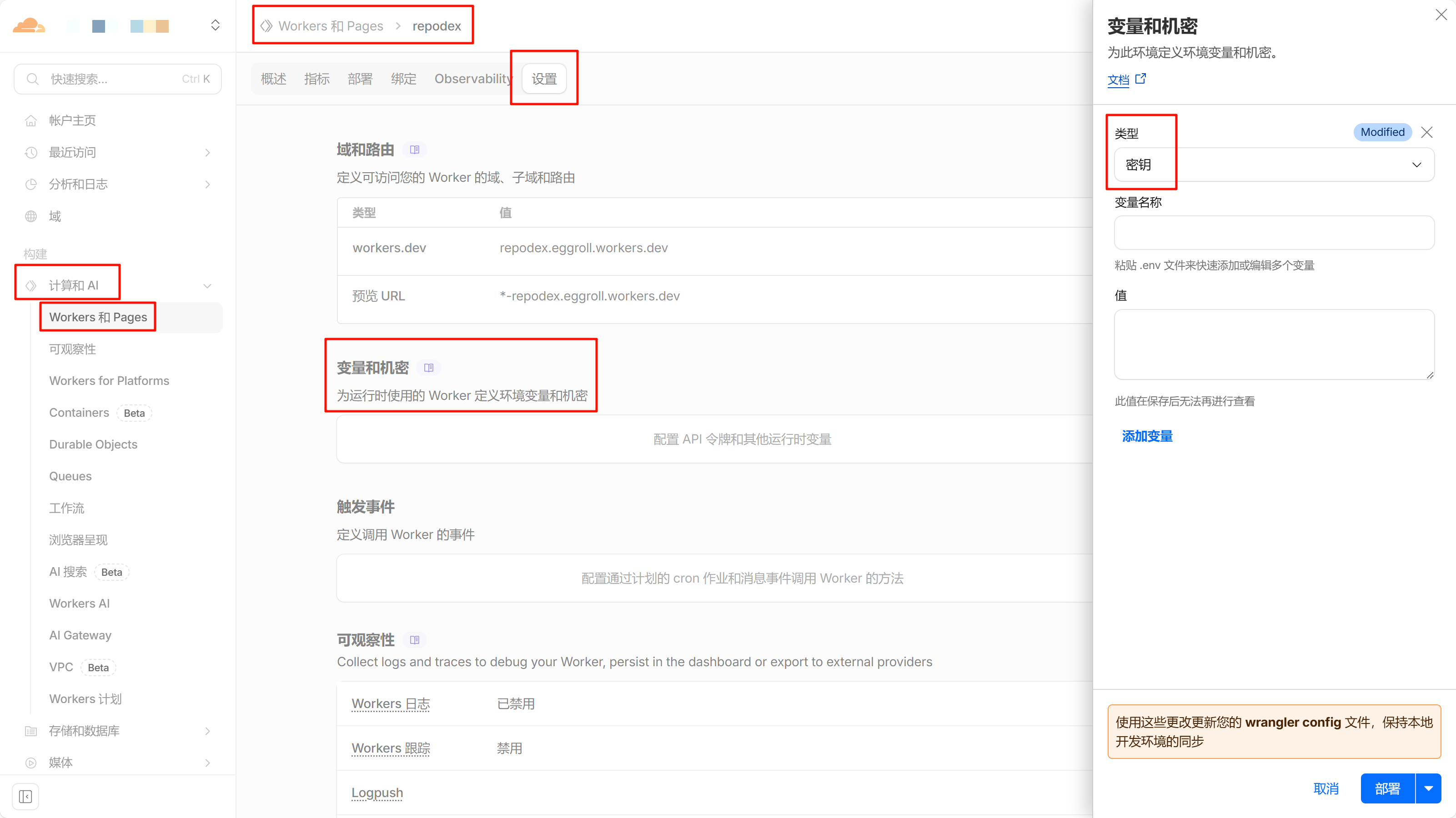
请添加以下机密,类型均为“密钥”:
USER:您预期的的登录用户名PSWD:您预期的登录密码REPO_INFO_TOKEN:上文【信息 4】
添加完成后,请部署。
自此,项目已经完全部署完成。您可以添加任意多个接入索引的仓库,网页不需要重新部署,会动态地获取新增的索引。
核心组件
文件索引生成器工作流
一套便于挂载到任何仓库的自动化工作流。
工作流的任务:
作为标准化挂件接入目标仓库后,当仓库任意分支触发代码推送,或通过手动方式启动时,即可执行该工作流。工作流会遍历仓库所有分支下的所有文件,生成统一的全局索引文件,随后将该索引文件推送至 Cloudflare KV 存储。
统计

鸣谢